In this section, we present a space optimization technique in the case the sender uses multiple TESLA instances for one stream.
Choosing the disclosure delay involves a tradeoff. Receivers with a low network delay welcome short key disclosure delays because that translates into a short authentication delay. Unfortunately, receivers with a long network delay could not operate with a short disclosure delay because most of the packets will violate the security condition and hence cannot be authenticated. Conversely, a long disclosure delay would suit the long delay receivers, but causes unnecessarily long authentication delay for the receivers with short network delay. The solution is to use multiple instances of TESLA with different disclosure delays simultaneously, and each receiver can decide which disclosure delay, and hence, which instance to use. A simple approach to use concurrent TESLA instances is to treat each TESLA instance independently, with one key chain per instance. The problem for this approach is that each extra TESLA instance also causes extra space overhead in each packet. If each instance requires 20 bytes per packet (80 bit for key disclosure and 80 bit for the MAC value), using three instances results in 60 bytes space overhead per packet. We present a new optimization which reduces the space overhead of concurrent instances.
The main idea is that instead of using one independent key chain per TESLA
instance, we could use the same key chain but a different key schedule for all
instances. The basic scheme works as follows. All TESLA instances for a stream
share the same time interval duration and the same key chain. Each key in
the key chain is associated with the corresponding time interval , and
will be disclosed in .![]() Assume that the sender uses instances of
TESLA, which we denote with . Each TESLA instance
has a different disclosure delay , and it will have a MAC key schedule
derived from the key schedule shifted by time intervals from the key
disclosure schedule. Let denote the MAC key used by instance
in time interval . We derive as . Note that we use HMAC as a pseudo-random function,
which is the same key derivation construction as we use in TESLA (see
section 2.1 and figure 1). In fact, the keys of the
first instance are derived with the same pseudo-random function as the TESLA
protocol that uses only one instance. The reason for generating all different,
independent keys for each instance is to prevent an attack where an attacker
moves the MAC value of an instance to another instance, which might allow it to
claim that data was sent in a different interval. Our approach of generating
independent keys prevents this attack. Thus to compute the MAC value in packet
in time interval , the sender computes one MAC value of the message
chunk per instance and append the MAC values to . In particular, for
the instance with disclosure delay , the sender will now use the
key as mentioned above for the MAC computation.
Assume that the sender uses instances of
TESLA, which we denote with . Each TESLA instance
has a different disclosure delay , and it will have a MAC key schedule
derived from the key schedule shifted by time intervals from the key
disclosure schedule. Let denote the MAC key used by instance
in time interval . We derive as . Note that we use HMAC as a pseudo-random function,
which is the same key derivation construction as we use in TESLA (see
section 2.1 and figure 1). In fact, the keys of the
first instance are derived with the same pseudo-random function as the TESLA
protocol that uses only one instance. The reason for generating all different,
independent keys for each instance is to prevent an attack where an attacker
moves the MAC value of an instance to another instance, which might allow it to
claim that data was sent in a different interval. Our approach of generating
independent keys prevents this attack. Thus to compute the MAC value in packet
in time interval , the sender computes one MAC value of the message
chunk per instance and append the MAC values to . In particular, for
the instance with disclosure delay , the sender will now use the
key as mentioned above for the MAC computation.
Figure 3 shows an example with two TESLA instances, one with a key disclosure time of two intervals and the other of four intervals. The lowest line of keys shows the key disclosure schedule, i.e. which key is disclosed in which time interval. The middle and top line of keys shows the key schedule of the first and second instance respectively, i.e. which key is used to compute the MAC for the packets in the given time interval for the given instance. Using this technique, the sender will only need to disclose one key chain no matter how many instances are used concurrently. If each disclosed key is bytes long, then for a stream with concurrent instances, this technique will save bytes per packet, which is a drastic saving in particular for small packets.
Iip3 Iip4 Kpip1 Kpip2 Kpip3 Kpip4 Kpip5 Kpip6 Kip3 Kip4 Kppip3 Kppip4 Kppip5 Kppip6 Kppip7 Kppip8
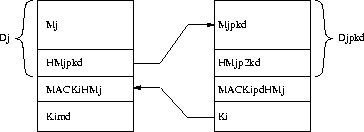
Figure 3: Multiple TESLA instances key chain optimization.