Course Syllabus
18-647: Computational Problem Solving
Spring 2023
Location: HH-1107
Class Lecture: Tuesday and Thursday, 9:30am–10:50am
Recitation: Friday, 10:00am–10:50am
Number of Units: 12
Recommended pre-requisites: 18-213/613, 18-645/646, 18-202 or equivalent
Instructor: Prof. Franz Franchetti
Office hours: Monday 2:00-3:00 p.m. or by appointment
Office location: HH A312, https://cmu.zoom.us/my/franzf
Email: franzf@ece.cmu.edu
Web: http://www.ece.cmu.edu/~franzf
Teaching Assistant: Naifeng Zhang
Office hours: Thursday 11:00am-12:00pm
Office location: HH 1306, https://cmu.zoom.us/j/5340779141
Email: naifengz@cmu.edu
Teaching Assistant: Sanil Rao
Office hours: Wednesday 1:00pm-2:00pm
Office location: HH 1306, https://cmu.zoom.us/j/310251213
Email: sanilr@andrew.cmu.edu
Course Support: Academic Services Center
Office location: HH 1113
Website: https://www.ece.cmu.edu/academics/academic-services-center.html
Canvas link: https://canvas.cmu.edu/courses/32631
ECE IT Helpdesk: HH A204 walk-in Monday–Friday 8:00am–5:00pm
email: help@ece.cmu.edu
Overview:
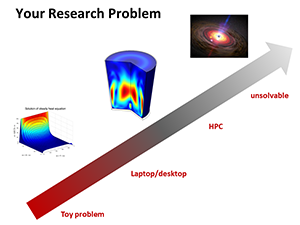
Computing platforms used in engineering span an incredible dynamic range from embedded and wearable processors through handhelds/laptops to high performance computing servers and the cloud. Similar engineering and AI/ML problems need to be solved across the entire dynamic range. When developing algorithms or solving R&D problems, one usually starts with Matlab and Python using frameworks like Torch, Spark, and TensorFlow, and only resorts to C/C++ only when needed. This course covers how to solve AI/ML and engineering research and development problems across the entire range of machines in a productive and performant way. It discusses how to scale problems from the initial concept stage usually executed on a laptop to more powerful computing systems like enterprise or HPC servers, GPU accelerated systems, and cloud computing platforms.
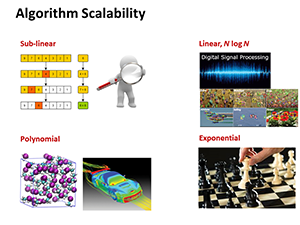
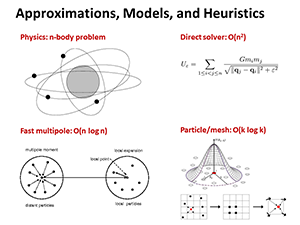
This course addresses a wide range of computational and informatics problem families from traditional numerical simulation and symbolic data processing to AI and machine learning problems. It covers the most important scalable parallel algorithms used in engineering computing, and discusses frameworks providing problem-specific and general implementation templates. It covers algorithm analysis from the numerical and complexity perspective, parallelization approaches and scalability, algorithm optimization, evaluation and analysis of results.
Students in this course learn to productively solve AI/ML and engineering research and development problems on advanced computer systems across the dynamic range of computing systems. Further, they learn to carry algorithms from the concept stage to efficient-enough scaled-up implementations necessary to solve large scale problem instances, or squeeze them into the small footprint of embedded and wearable devices. Students will solve assigned homeworks and do a final blog post about lessons learned.
Brief List of Topics Covered:
- Parallel algorithms, scalability, and numerical analysis of these algorithms
- Software stack and hardware for computational engineering and AI/ML problems
- Hardware and software available to CMU students (on-site, cloud, NSF XSEDE)
- Frameworks and execution environments for quick problem solving
- How to scale from initial concepts to large-scale problems
- Next steps: How to transition to C/C++ with CUDA/OpenCL, OpenMP, MPI etc.
Download the syllabus here.
 |
 |
Tentative Course Calendar
| Date | Day | Class Activity |
| January | ||
| 17 | Tues. | State of computing: What is the current state of the art from embedded devices through desktops, servers, and consumer systems all the way to cloud, HPC, and supercomputing |
| 19 | Thurs. | Computer architecture: Relevant computer architecture concepts |
| 24 | Tues. | Software stack: ISA, operating system, virtualization, messaging, containers |
| 26 | Thurs. | Mathematics for Engineers: The central role of numerical linear algebra. Release HW 1 |
| 31 | Tues. | Algorithm analysis, scalability, complexity: Getting answers in time |
| February | ||
| 2 | Thurs. | The ECE Computing Environment: number cluster, Andrew systems, capability machines, GPU access, cloud access, Pittsburgh Supercomputing Center and XSEDE |
| 7 | Tues. | Parallelization: Sequential vs. parallel algorithms, scalability vs. performance. HW 1 due, release HW 2 |
| 9 | Thurs. | Need for speed: Principles of code optimization, when and how to optimize code |
| 14 | Tues. | Cloud computing and HPC: Amazon EC2/Windows Azure/Google Cloud, Computational Grids, Scientific Workflows, Computing Centers, ECE ITS |
| 16 | Thurs. | Guest Lecture: Quantum Computing and Quantum Algorithms |
| 21 | Tues. | Numerical Analysis: How good are your answers? How to make them better? HW 2 due, release HW 3 |
| 23 | Thurs. | Scalable algorithms: Dense numerical linear algebra, CNNs/DNNs/ FFTs |
| 28 | Tues. | Scalable algorithms: Graph algorithms and sparse numerical linear algebra |
| March | ||
| 2 | Thurs. | Scalable algorithms: ODE and PDE solvers, stencils, filters, discretization |
| 14 | Tues. | Scalable algorithms: Discrete and continuous optimization, ML training. HW 3 due, release HW 4 |
| 16 | Thurs. | Scalable algorithms: Informatics, symbolic computing, higher level AI algorithms |
| 21 | Tues. | Scalable algorithms: Statistics: Monte Carlo, MCMC, statistical machine learning |
| 23 | Thurs. | Data: Obtaining real data sets, data visualization, data bases, data stores, file systems |
| 28 | Tues. | Modern CPUs: Super-Scalar Out-of-order, multicore |
| 30 | Thurs. | Class Cancelled |
| April | ||
| 4 | Tues. | Modern CPUs: Vector Extensions HW 4 due, release HW 5 |
| 6 | Thurs. | Hardware Acceleration: GPUs, FPGAs, TPU, Tensor Cores, . . . |
| 11 | Tues. | Guest Lecture: Software Engineering vs. Performance Engineering |
| 18 | Tues. | Guest Lecture: Pittsburgh Supercomputing Center and Usable HPC and High Performance AI/ML |
| 20 | Thurs. | From productivity to performance: C++, OpenMP, MPI, CUDA, Autotuning. HW 5 due |
| 25 | Tues. | Research Talk: SPIRAL: Formal Software Synthesis of Computational Kernels |
| 27 | Thurs. | Summary and Beyond. Blog post due |
 |
 |
 |
 |
 |
 |
Homework and Blog Post Logistics and Requirements
Machines
In this course we will use a large variety of machines in the homeworks and projects:
- Large Linux servers with direct ssh access. The machines we will access are the ECE number cluster and the data science cloud.
- Large number of small Linux machines in high throughput mode via ECE's HTCondor.
- HPC multicore nodes and multi-node configurations with and without GPUs via a batch system at PSC and CMU/MechE.
- Hadoop/Spark/Tensorflow with and without GPUs at PSC.
- Special hardware at PSC: Bridges AI multi-GPU resources (HPE Apollo and DGX-2) and large memory machines.
- AWS instances with or without multicore and GPU support.
Software Platforms
In the course we will try out a number of high-level languages and libraries in these languages:
- Python with NumPy, SciPy, and matplotlib
- R with CRAN packages
- Matlab
- Mathematica
- Haskell
- Frameworks: Torch, Theano, OpenCV
- High-end engineering software
- C/C++ with HPC math/ML libraries
Algorithms
We will use algorithms covered in the lecture as simple examples to experiment across the machines and software platforms. Students either implement the algorithms themselves or find implementations online, and then run them on the target machines to perform scalability studies. Algorithm groups targeted in the homeworks are as following:
- Dense numerical linear algebra, CNNs/DNNs/FFTs
- Graph algorithms and sparse numerical linear algebra
- ODE and PDE solvers, stencils, filters, discretization
- Discrete and continuous optimization, ML training
- Informatics, symbolic computing, higher level AI algorithms
- Statistics: Monte Carlo, MCMC, statistical machine learning
- Deep Learning, Big Data Analytics
MS Homework 1—5 Deliverables
Homework 1 to 5 will have as deliverables examples that run the specified/chosen algorithms on the specified/chosen machines for a range of problem sizes. The homework submission consists of the following:
- The source code for the algorithm, with source attribution as applicable
- The necessary data files
- All necessary scripts and make files
- The captured output of the submission runs
- Measurements in CSV files and performance plot
Blog post—Deliverables
As final project students submit a blog post addressing the following aspects of one of the homework problems:
- Problem specification: explain what problem you are addressing and where it is used.
- Algorithm: describe the algorithm you used.
- Hardware and software: describe the hardware platform and software infrastructure you used.
- Outcome: describe the result you obtained and how larger computing resources were necessary.
- Scalability and complexity: describe the algorithm's complexity, how the algorithm scales with problem size, and how it scales number of processors/cores in strong and weak scaling sense.
- Quality of the result: assess the numerical or approximation quality of your result.
- Performance anyalysis: measure the runtime behavior, model fit it to the theoretical growth behavior, and assess the efficiency of the implementation.
- Suggested performance optimization: Assume a limited engineering budget but the need for a faster solution. Suggest which parts of the algorithm one would optimize and what optimization approach and target hardware should be used.