| |
DARPA PERFECT: |
| |
|
| |
Energy Efficient High Performance through Application-Specific Processor/Program Co-Synthesis
(HR00111320007)
|
| |
|
| |
Franz Franchetti (PI), José M. F. Moura (Co-PI), James C. Hoe (Co-PI), Larry Pileggi (Co-PI), Mike Franusich (Co-PI)
Post-Docs: Yusuf Adibelli, Nikos Alachiotis, Qi Guo, Tze Meng Low, Kaushik Vaidyanathan
PhD Students: Thom Popovici, Fazle Sadi, Kuntal Shah, Richard Veras, Guanglin Xu
Engineers: Brian Duff, Jason Larkin
Alumni: Berkin Akin, Aliaksei Sandryhaila, Ekin Sumbul, Qiuling Zhu |
|
|
|
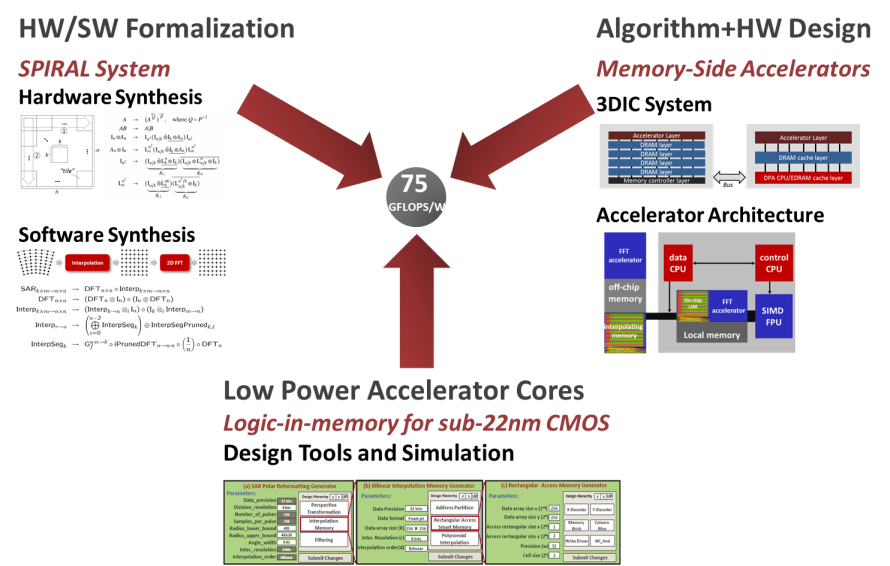
Approach
The DARPA PERFECT Program develops technology to achieve power efficiency of 75 GFLOPS/W at 7nm for DoD-relevant applications. Our approach is to deploy algorithm/architecture co-synthesis that leverages 3D chip stacking technology. We are targeting the PERFECT goal of 75 GFLOPS/W from three complementary angles: |
|
• Hardware/software co-synthesis based on the SPIRAL technology.
• Memory-side Accelerators, a highly configurable architecture for near memory computing.
• Low power accelerators based on the logic-in-memory and 3DIC technology.
|
|
The core idea of our strategy is that reaching the PERFECT goal requires to leverage domain knowledge, automatic design space exploration, and leveraging of low-power technology like 2.5D and 3D interconnection/stacking and logic/memory integration that become possible at sub-20nm technology nodes. Further, as evidenced by its hardware and software design tools CMU recognizes the need for industry-grade tools to enable integration with the PERFECT architecture and the need for eventual technology transition. |
|
|
|
|
|
|
|
Results
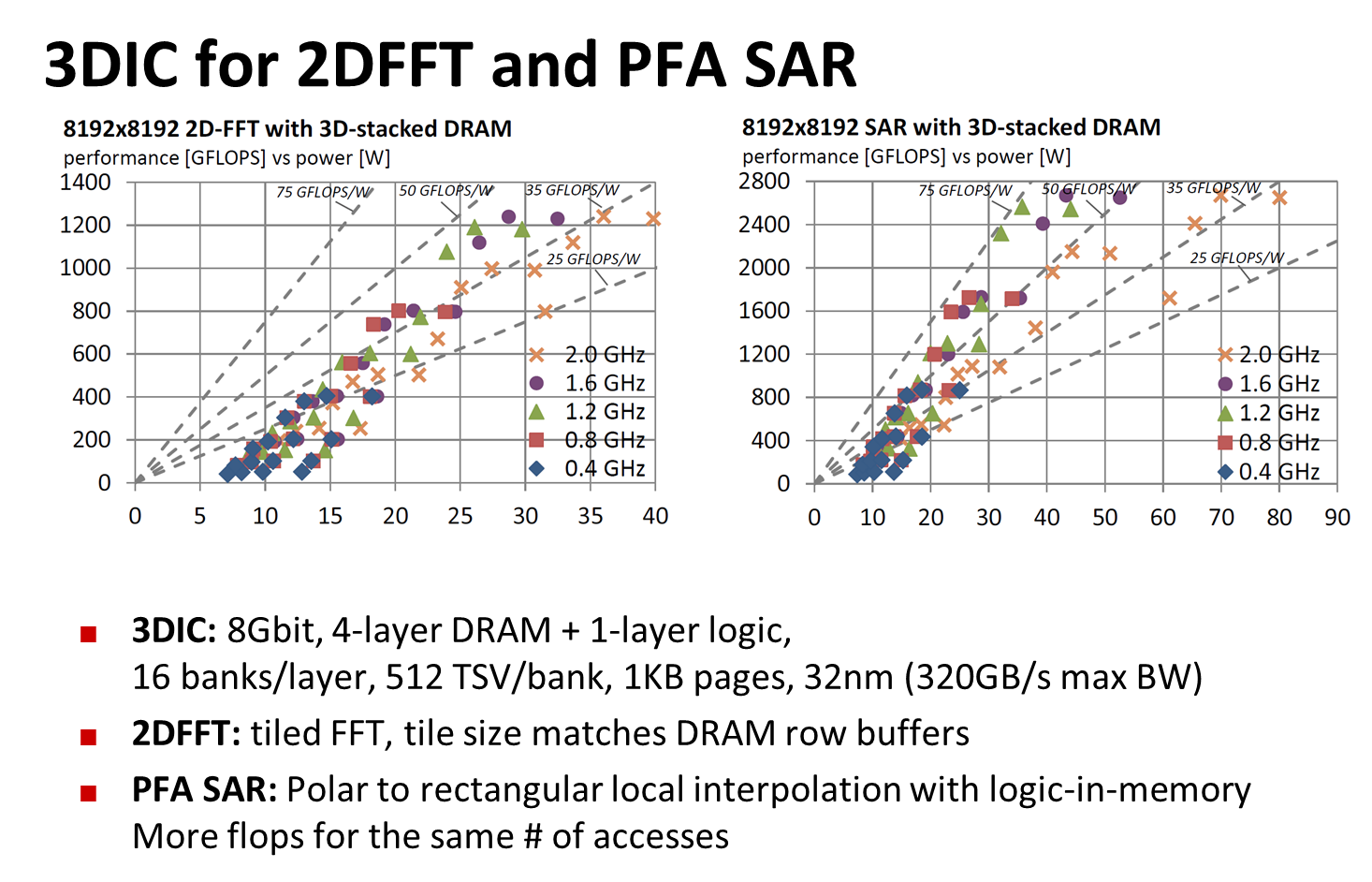
Our major accomplishments in Phase 1 of PERFECT are all demonstrated on a simulated 3DIC system (4 layers of 2Gbit DRAM, 1 layer of logic 32nm technology node, run at 1GHz – 1.3 GHz). The major tangible accomplishments are three near-DRAM accelerators that have been demonstrated in Phase 1 in detailed full-system (DRAM and logic) simulation (Figure 3 and 4): |
|
• 2D FFT performing at 40 GFLOPS/W, up to 8k x 8k single-precision floating-point. Data resides in DRAM before and after computation. 1D FFT and 3D FFT also demonstrated.
• Polar formatting SAR at 71 GFLOPS/W, up to 8k x 8k, 91 dB PSNR compared to a Matlab double-precision “gold standard” implementation of SAR with FFT-based interpolation.
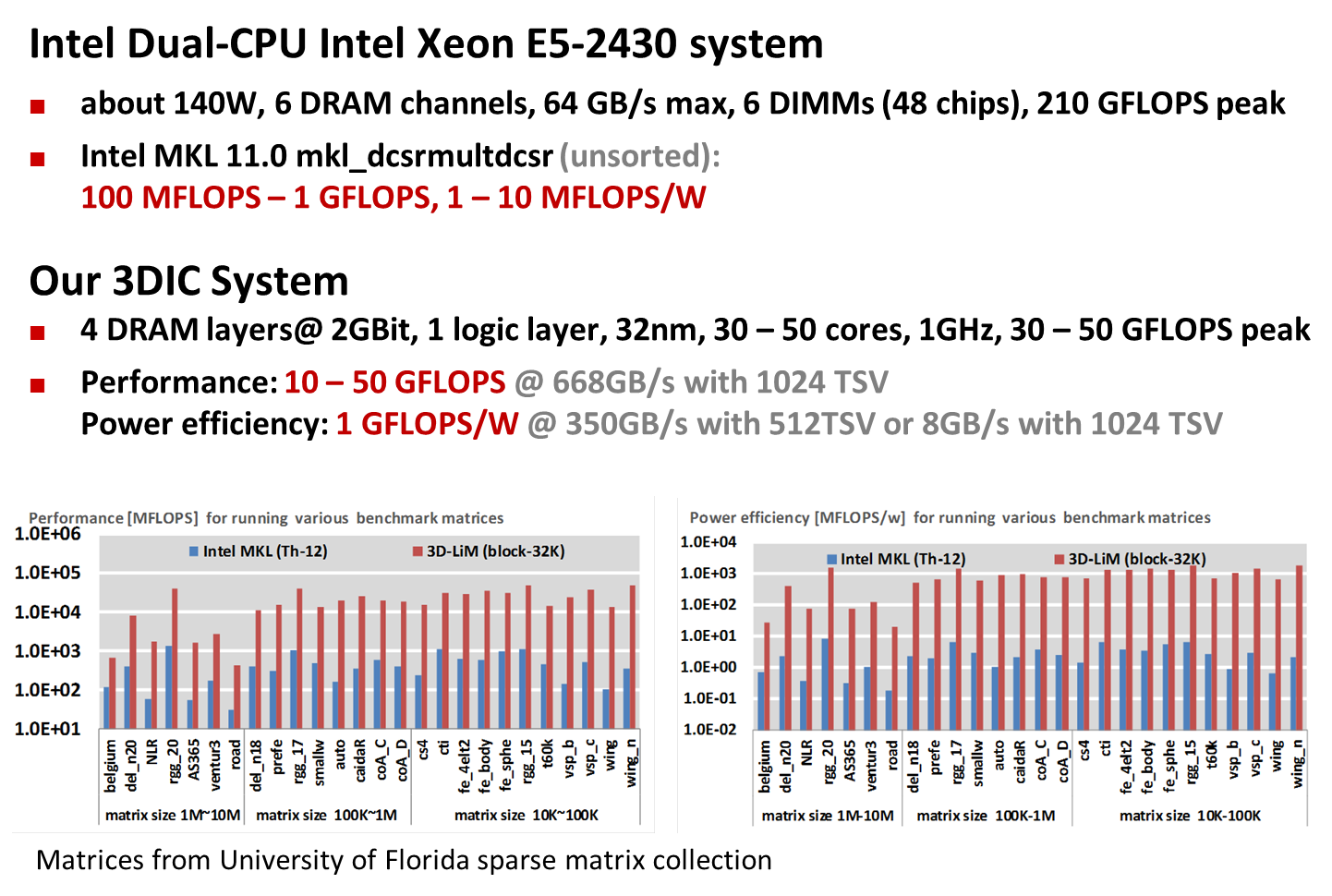
• Sparse matrix-matrix multiplication at 1 GFLOPS/W, demonstrated for matrices of the University of Florida sparse matrix collection. This is 100x speed-up and 1000x improved power efficiency when compared to the state-of-the-art (Intel and Nvidia).
|
|
These accelerators are components of the DPA architecture and the key to reaching the PERFECT goal of 75 GFLOPS/W at 7nm with DPA. CMU uses an elaborate setup of industry standard simulation tools to obtain the 32nm performance and power estimates. All steps in the simulation were provided to the TAV. CMU also performed thermal simulations and addressed power distribution to establish that the designs can be built with current or emerging 3D technology. |
|
|
|
|
|
|
| |
|
|
|
|
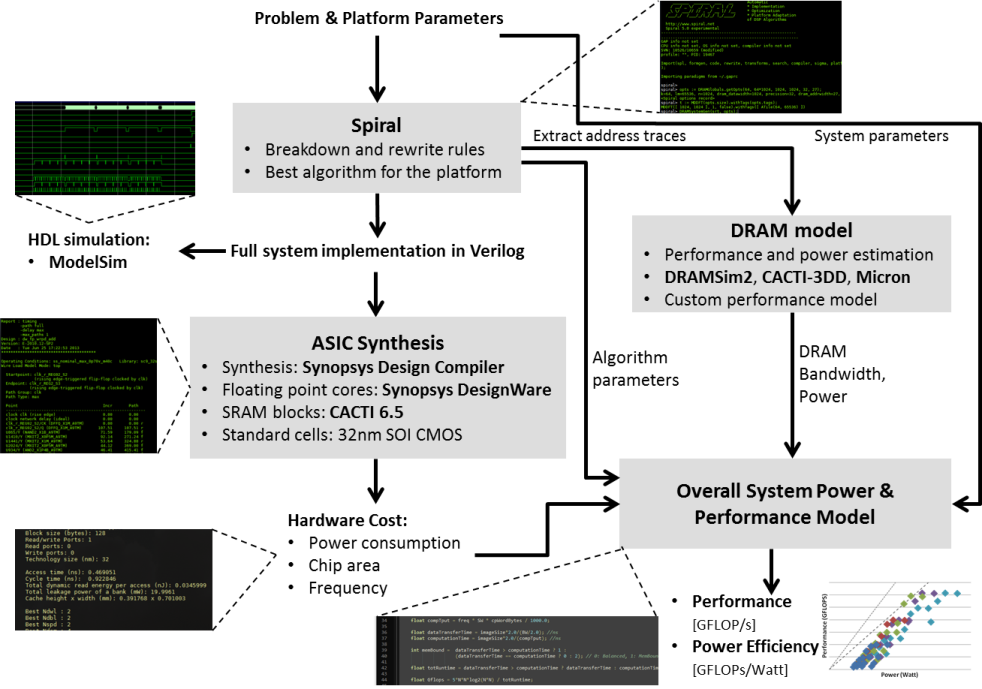
Design and Simulation Tools
Our results were obtained using our tools for design space exploration. We demonstrated for all these kernels the capability to generate and evaluate many design points with various trade-offs to enable users to reach a certain goal for one metric (e.g., at least 1 TFLOPS or no more than 40 Watt) while optimizing the other metric. |
|
|
|
|
|
|
|
Publications
B. Akin, F. Franchetti, J. C. Hoe
Data Reorganization in Memory Using 3D-stacked DRAM
42nd International Symposium on Computer Architecture (ISCA), 2015.
H. E. Sumbul, K. Vaidyanathan, Q. Zhu, F. Franchetti, L. Pileggi
A Synthesis Methodology for Application-Specific Logic-in-Memory Designs
Proceedings of the 52nd Design Automation Conference (DAC), 2015.
D. A. Popovici, F. Russell, K. Wilkinson, C-K. Skylaris, P. H. J. Kelly, F. Franchetti
Generating Optimized Fourier Interpolation Routines for Density Functional Theory Using SPIRAL
29th International Parallel & Distributed Processing Symposium (IPDPS), 2015.
Q. Guo, N. Alachiotis, B. Akin, F. Sadi, G. Xu, T-M. Low, L. Pileggi, J. Hoe, F. Franchetti
3D-Stacked Memory-Side Acceleration: Accelerator and System Design
2nd Workshop on Near Data Processing (WONDP) in conjunction with the 47th International Symposium on Microarchitecture (MICRO-47), 2014.
B. Akin, F. Franchetti, J. C. Hoe
Understanding the Design Space of DRAM-optimized Hardware FFT Accelerators
Proceedings of the 25th International Conference on Application-Specific Systems, Architectures and Processors (ASAP) 2014, pages 248-255.
B. Akın, F. Franchetti, J. C. Hoe
HAMLeT: Hardware Accelerated Memory Layout Transform within 3D-stacked DRAM
Proceedings of High Performance Extreme Computing Conference (HPEC) 2014.
Best Paper Award
F. Sadi, B. Akin, D. T. Popovici, J. C. Hoe, L. Pileggi, F. Franchetti
Algorithm/Hardware Co-optimized SAR Image Reconstruction with 3D-stacked Logic in Memory
Proceedings of High Performance Extreme Computing Conference (HPEC) 2014.
Rising Stars Session
Q. Zhu, C. R. Berger, E. L. Turner, L. Pileggi, and F. Franchetti:
Local Interpolation-based Polar Format SAR: Algorithm, Hardware Implementation and Design Automation
The Journal of Signal Processing Systems. Springer, 2013, VLSI1782R2.
B. Akin, F. Franchetti, J. Hoe
FFTs with Near-Optimal Memory Access Through Block Data Layouts
Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2014.
Q. Zhu, B. Akin, H. E. Sumbul, F. Sadi, J. Hoe, L. Pileggi, F. Franchetti
A 3D-Stacked Logic-in-Memory Accelerator for Application-Specific Data Intensive Computing
Proceedings of IEEE International 3D Systems Integration Conference (3DIC) 2013, pages 1-7.
Q. Zhu, H. E. Sumbul, F. Sadi, J. Hoe, L. Pileggi, F. Franchetti
Accelerating Sparse Matrix-Matrix Multiplication with 3D-Stacked Logic-in-Memory Hardware
IEEE High Performance Extreme Computing Conference (HPEC), 2013, pages 1-6.
Best Paper Award
|
|
|
|
|
|