 |
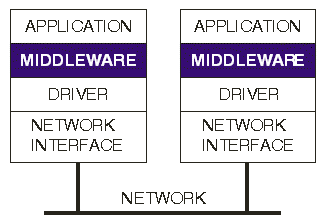
| Figure 1. Middleware performs fault injection on network messages. |
As embedded communication networks pervade widely fielded safety-critical distributed systems, it is important to understand their robustness. Middleware fault injection offers advantages in flexibility and cost over adding specialized fault injecting network nodes. The research goal is accelerated testing of an automated vehicle system with respect to transient communication network faults.
Embedded communication networks are playing an increasingly important role in safety-critical systems. Networking is being used to give greater system design flexibility, improve diagnosability, and reduce wiring weight/size/cost. As an example, prototype vehicles are using “drive-by-wire” capabilities, in which critical functions are performed entirely by networked computers. As this shift toward digital technology takes place, the importance of control system dependability will increase dramatically.
While techniques for constructing dependable networks have been studied for many years, large scale applications such as automobiles have somewhat different design concerns than traditional aerospace and military uses. For example, cost constraints limit the redundancy that can be installed, and the large installed base makes it likely that even improbable failure modes will be experienced somewhere within an operating fleet on a regular basis. For example, an “extremely improbable” event in aviation might be defined as occurring at a rate of 10-9 failures per hour.[1] If one applies this to airlines tracked by the U.S. government [2], this yields one failure per 73 years based on 13.7 million fleet operating hours in 1996. However, the fleet of 200 million U.S. ground vehicles experiences about four orders of magnitude more usage than airline equipment. Using U.S. government data for vehicles [3], that same “extremely improbable” aviation failure rate yields 82 failures per year (one every 4.5 days) based on 2.469 trillion vehicle miles traveled if one assumes an estimated average speed of 30 miles per hour. Vehicle failures caused by merely “improbable” instead of “extremely improbable” failures would, of course, be more numerous.
Because even extremely improbable (from a single unit point of view) failures will occur as a matter of course within a large fleet, it is important to understand the robustness of embedded control systems when experiencing a large variety of anticipated and unanticipated failures. A specific area of concern is in embedded control networks, which typically have a non-negligible transmission error rate.
One would hope that typical product testing would find and correct system-level problems caused by message transmission errors. The problem with relying upon normal product testing, however, is that improbable events are unlikely to be observed in any reasonable amount of time. Analysis and simulation can be used to help predict worst-case behavior. But, these approaches are difficult to apply on a system-level basis because of the expense of modeling complete electromechanical systems.
Fault injection is an alternative to modeling, and is used to probe the behavior of distributed systems. A typical approach is to add a commercially available fault injection node to a network. Such an injection node has the ability to selectively corrupt messages as they appear on the network. This approach can provide the following capabilities:
However, there are limitations to such hardware fault injection. The hardware fault injector can be expensive, which is an important consideration in cost-sensitive, low-margin businesses such as the automotive industry or university research. Additionally, hardware fault injectors are not able to “see inside” the various nodes on the network, restricting the types of errors they can inject and data they can collect.
More recently, work has been performed in software-implemented fault injection (SWIFI) for communication networks. For example, Stott et al. [4] modified high-speed LAN host interface board control software to test system robustness in the face of injected faults. The automated vehicle application that will serve as our experimental platform uses the Controller Area Network (CAN), which is the de-facto standard automotive control network. This brings with it the benefits of having a mature protocol definition and implementation. However, it also makes it essentially impossible to perform fault injection within the network controller, since the controller is encapsulated within a fixed-design chip.
|
| Figure 1. Middleware performs fault injection on network messages. |
A generalized SWIFI approach for network messages that avoids the need to change network controller software is the use of middleware (Figure 1). For example, Dawson et al. [5] use middleware with a script-driven technique to test protocols. Our work also uses middleware SWIFI, but for the purpose of testing application robustness, and with special techniques required by the use of a low-speed control network. Middleware fault injection has advantages beyond hardware fault injection, including the ability to:
Because low-speed control networks can have sensitive timing constraints, our SWIFI approach must find a way to coordinate system-wide fault injection without interfering with system timing. Furthermore, the use of an off-the-shelf protocol chip thwarts attempts to inject a detectably corrupted message. These goals can be accomplished with the use of background messages and a single-bit fault flag within message data fields.
System failure scenarios can be set up and initiated using low-priority “background” messages from a laptop computer. Since there is some slack bandwidth available in a typical system, and CAN supports global prioritization of messages, this approach leaves the system essentially unperturbed. A failure scenario is a list of actions initiated upon request from an experimenter, and takes effect when an initiating background message has the opportunity to be transmitted.
Within a failure scenario, delays are readily introduced by individual transmitters. More problematic is the generation of message failures. The CAN controller does not permit injecting a detectable data error, because it computes the CRC field in hardware. However, there are three approaches that can be used in various circumstances:
The current state of the work is that initial middleware software is operating under the QNX real-time operating system with CAN hardware. Simulation and analytic modeling will be used to determine appropriate failure scenarios to inject so as to be representative of failure rates experienced in a large deployed fleet. Ultimately, faults will be injected on an operating automated vehicle to characterize system robustness and recommend changes to control algorithms, if necessary, to achieve required system-level safety goals.
This work is sponsored by ONR contract N00014-96-1-0202, and by USDOT under Cooperative Agreement Number DTFH61-94-X-00001 as part of the National Automated Highway System Consortium (NAHSC).
[1] Villemeur, A., Reliability, Availability, Maintainability and Safety Assessment, John Wiley & Sons, 1992 (pg. 533).
[2] U.S. Bureau of Transportation Statistics, Airline Traffic Statistics spreadsheet, http://nasdac.faa.gov/bts/btsfrm41.xls accessed April 10, 1998.
[3] U.S. Department of Transportation, NHTSA, Traffic Safety Facts 1996, http://www.nhtsa.dot.gov/people/ncsa/Overvu96.pdf, accessed April 10, 1998
[4] Stott, D., Ries, G., Hsueh, M. & Iyer, R., “Dependability analysis of a high-speed network using software-implemented fault injection and simulated fault injection,” IEEE Trans. Computers, 47 (1) 108-119, January 1998.
[5] Dawson, S., Jahanian, F., Mitton, T. & Tung, T., “Testing of fault-tolerant and real-time distributed systems via protocol fault injection,” FTCS ‘96, pp. 404-414.