Carnegie Mellon University
18-849b Dependable Embedded Systems
Spring 1998
Authors: Michael Collins
As systems approach the end of their usable lifetime, individual components may fail without the integrity of the system being compromised. In some cases, it is possible to continue to use a system even as its component subsystems fall apart. For various reasons, operators may elect to operate systems after their expected lifespan, and designers should be aware of the factors that lead to these decisions.
Mortality calculations are an important part of a product's life cycle. Ideally, an engineer should know how long a system will last for, and a company can then know how long they will have to provide maintenance services for that system. From the customer perspective, the lifespan calculation serves as a useful life estimate: the system should be replaced before or at the end of its lifespan and customers, for a multitude of reasons, generally do. However, there are mitigating circumstances which may keep a system operating after its estimated lifespan. These circumstances can range from customer loyalty to a product line to spectacularly botched system upgrades; and despite the best intentions and loudest warnings of system designers, systems will be used past the end of their lifespan. It is consequently important not only to understand that this does happen, but why.
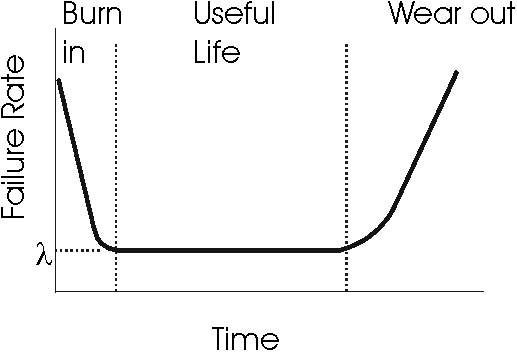
The bathtub curve illustrates the expected failure rates for systems. As can be seen, systems start out with a high failure rate (the infant mortality period), then settle down to a life of fairly stable operation. However, as the system reaches the end of its lifespan, its failure rate increases once again as various physical failures accumulate: lubricants go dry, metal rusts, rubber becomes brittle, all the various processes of wear and tear eventually cause a system to fail regardless of how well it is designed. End of lifespan wearout is concerned with how systems behave once they reach this far end of the curve.
End of lifespan behavior is a somewhat thorny issue when dealing with safety critical systems. Systems should fail in a safe fashion, but the unpredictable nature of failure modes means that the safest option is to completely shut off and remove the system. Unfortunately, there are a variety of systems, such as Air Traffic Control systems, which require continuous operation. Frustratingly, these systems are also inordinately difficult to replace.
In other cases, shutting off a segment of a system may have political implications. Cars tend to be sold and resold, going through one or more income brackets with each sale. As cars become more sophisticated, certain expensive (and sophisticated) systems are becoming commonplace. Cruise control is a good example. A car without cruise control can still operate, but a faulty cruise control system can easily cost lives. While the obvious solution is to completely eliminate the cruise control system once it reaches the end of its safe lifespan, this raises unpleasant legal issues. As noted below, systems tend to be passed down in hierarchies - in the case of cars, the hierarchy is economic. Shutting down cruise control could be considered the equivalent of limiting safety to those who can afford it.
Safety regulations, and technological advances usually make the complete replacement of a system preferable to continually repairing a system. When dealing with electronic systems, the impetus to replace is further strengthened by Moore's Law: there is little reason to replace a ten year old system when present systems are at least one hundred times as powerful. In the case of consumer electronics and office equipment, systems rarely reach the end of their lifespan because the external pressures to replace are just too great.
However, While eliminating a system may be a technically sound decision, there are valid reasons for keeping a system up to or past its lifespan. Economically, repairing a system is a cheaper short term cost than outright replacement, and when an organization is living close to profit margins, repair costs become more attractive. Although the aggregate cost may be more expensive than outright replacement, there are organizations which cannot produce enough capital to replace their systems outright. The former Soviet Union is running into this problem with certain infrastructural systems.
Beyond the economic factors, the single most powerful motivator for system maintenance is operator conservatism. Retraining is expensive, and in the case of critical systems, operators can't afford the learning curves and mistakes associated with learning everything from scratch[D'yakov96]. Consequently, video editors will continue to use Amiga computers as their primary editing platform long after the manufacturer has filed for bankruptcy.
While its possible to predict the lifespan of a product, predicting failure modes is extremely difficult. This difficulty is compounded when trying to predict failure at the end of lifespan. While environmental testing can simulate aging to some extent, it cannot truly approximate all the vagaries of a full lifespan in the field.
When people see value in a system, they naturally build support structures to maintain the system. These structures can range from companies (such as Mentec, which specializes in year 2000 remediation of PDP-11 systems), to information repositories or user groups. The unpredictable nature of end of life failure, and the scarcity of replacement parts, means that these shops, clubs or organizations are necessary for the continued maintenance of the system. In many cases, systems have been completely reverse-engineered.
These maintenance strategies can be quite ingenious and also enter into the area of customer circumvention. By dint of years of experience, these organizations can acquire more practical knowledge about a system than the system's designers. Engineers maintaining these systems can develop extensive cannibalization strategies ranging from closets of spare parts salvaged from otherwise dead systems to private businesses devoted to hunting down (or, in some cases, manufacturing) antique hardware.
These repair organizations have acquired a new strength with the explosion of the World Wide Web. Societies for maintaining hardware ranging from Amigas to antique video game systems have built web sites and collated their information repositories. Some examples of these web-based organizations are listed below.
Just because a system is replaced does not mean that the original system is thrown out. Actually, depending on the type of system, it may not be thrown out for quite a while. In many cases, organizations develop explicit replacement hierarchies, handing hardware down from
In organizations, these hierarchies are usually determined by the original purchase. An informal survey of CMU's research divisions introduced three different replacement hierarchies:
In these cases, replacement hierarchy was often a political decision as much as a technical one.
Maintainers often acknowledge these replacement hierarchies in their maintenance strategies. In a large office where the bosses may run hardware three generations younger than their secretaries, backwards incompatibility can become a serious concern. Many of the maintainers interviewed discussed downgrading policies. On receiving a new machine, the maintainer would install an approved suite of office tools, usually a least one software generation behind the latest version. This intentional downgrade strategy helped eliminate incompatibility problem and also gave the maintainer reduced the chronic bugs to a known set.
In the case of embedded systems, replacement hierarchies tend to be economic rather than organization. Cars, for example, are generally resold in a downward economic spiral, going into lower income brackets with each resale.
It's debatable whether software failure should be considered an end of life issue. Since software failure is usually the result of the software attempting to process extraordinary input, rather than the software itself collapsing. Software rot is usually a result of changing specifications or demands, not semicolons devolving into commas.
There are, however, certain software problems which can be considered end of life issues. A good example are roll over errors: software problems caused when a counter reaches the limits of its representation (e.g., 256 for a byte). Depending on the nature of the counter, roll over errors can lead to various failures during roll over period. Currently, the most well publicized example of a roll over failure is the Year 2000 problem.
In contrast to software failures hardware failures are usually accumulative. A software failure may only show up under special conditions, a hardware failure is more likely to be chronic. Software failures involve spot redesign, while hardware failures can involve a traditional repair or replacement. In fact, since mechanical systems are not as often upgraded, it may be more feasible to repair mechanical systems while replacing electronic ones.
In general, computer systems are not kept around for their full lifespan. Moore's law (which states that chips double in capacity every 18 months), ensures that today's state of the art will be junk in ten years. Legislative requirements (especially environmental legislation), market competition and a score of other factors indicate that replacement is preferable to repair. Consequently, there is a question not only of how you repair and maintain ancient systems, but why.
Embedded appear to have a different cost model than desktop systems, largely because embedded systems consist of both a mechanical and a computer portion. While embedded systems will face the same kind of legislative and competitive factors that encourage replacement over repair, they do not necessarily become obsolete as quickly. While the computer portion of a system (the microchips and associated firmware) will rapidly fall behind on the technology curve, the mechanical systems do not. Mechanical repairs and tune ups can be cheaper than outright replacement in that case. An example of this can be seen in Uzbekistan, where several control facilities were replaced with a pair of Pentium based controlling computers [Westergaard98].
For almost all systems, embedded or desktop, operator conservatism is one of the most important motivators for keeping the system alive. Operators may be comfortable with a particular hardware system or software package, and given the training time required to learn a new package, arrange to use the older one. Video editors, for example, still use the Amiga computer while the hardware platform has been effectively dead for years.
For desktop systems, one of the primary reasons for maintaining ancient systems is data integrity. Year 2000 remediators argue endlessly about the benefits of two alternate formatting schemes: full expansion and windowing. In windowing, the software picks a 'pivot date' and says that all years before that pivot date are in the 21st century, all years after that are in the 20th. Full expansion reformats all dates from their two digit century implicit format to a four digit century explicit format. Windowing is currently preferred as a quicker and cheaper format, because while full expansion is more thorough, the manpower required to rewrite several billion records to four digit dates is daunting.
There are other reasons. Money plays a large part in many repair decisions: repairing a system can be expensive, but in the short term it's generally less expensive than replacing the system. There are also systems (such as the ATCS) which require continuous operation, making replacement prohibitively difficult. Finally, there are systems which are kept around until there is no other option: the IRS has a poor track record for systems upgrades.
There really aren't that many tools available for end of life maintenance. As noted above, by the time you reach the end of the lifespan, the preferred solution is to junk the system. I have included several hyperlinks to repair societies and organizations which maintain antique systems as examples.
The Year 2000 problem has introduced several remediation tools which have gotten more sophistication as we approach the deadline. Arguably, the majority of repair decisions in end of life are managerial and economic, not necessarily technical.
Systems will be used past their expected lifespan and engineers should recognize this when designing their systems. In particular, systems consist not only of the components, but the replacement and support chain for maintaining that system. If a system is seen as valuable, it will outlast the official support structure and build new support systems. The existence of societies and companies dedicated to maintaining antique systems indicates that the operators find value in the system beyond the calculated lifespan.
The wearout and replacement requirements surrounding electronic and mechanical systems differ. Although certain common factors (such as emissions quality standards) can motivate replacement for both systems, electronic systems usually reach obsolescence far before they reach end of life. Consequently, electronic systems usually are replaced before being repaired. Mechanical systems are usually repaired before replacement. Embedded systems are best considered as two distinct entities: the electronic/control component and the mechanical portion.
There are few papers covering end-of-life wearout and replacement, the best ones I have found focus on the impending collapse of the former Soviet Union's infrastructure.
The following links provide a feeling for the repair and maintenance organizations and subcultures in existence.
(Un)fortunately, this isn't a heavily researched topic, and most of the information I have acquired I have gotten through interviews. Looking at resale patterns would be intriguing, especially when relating to military hardware.