Distributed systems can be a powerful tool for providing increased computing power and lower monetary price at the cost of higher system complexity. Distributed systems consist of multiple computational nodes and communication channels between them. The benefits lie in dividing the computations that need to be done among the nodes, and coordinating their activities to achieve higher performance. This coordination, however, requires synchronization mechanisms and protocols to control the system. Once this is done, the system can gain flexibility as well, becoming able to tolerate faults through reconfiguration, graceful degradation, and voting. If the system is available to multiple users, then security mechanisms are also necessary to protect users of the system and their data. With the increasing importance of the Internet and networks, distributed systems are becoming more frequently used by embedded system designers, and while there are tools to aid them, the increased complexity must be carefully managed to gain the most benefit.
Distributed systems are becoming more common as the cost of networks goes down and the need for computing goes up. Distributed systems consist of multiple computational nodes and a network of communications channels between them. What distinguishes them from ordinary networked computers is that the system as a whole appears as a single node from a user's point of view. These systems are typically used to bring computation physically closer to where it is needed, or to increase the computing power available at a lower cost than a single processor design. In the form of clusters, distributed systems are increasingly being used to replace more expensive supercomputers and mainframes. In embedded systems, distributed designs appear in applications varying from automotive controls, where distributed sensors and controllers do more work than a single processor could coordinate, to automatic teller machines, which must connect to the databases of financial institutions, to WebTV boxes, which are exposed to all the power and danger of the Internet. As the Internet becomes more prominent and connectivity becomes more important, embedded systems designers are going to have to become more knowledgeable about distributed system design, and given the nature of many embedded systems, they are going to have to know how to make dependable embedded systems.
Dependability is usually divided into four areas: reliability, availability, safety, and security. Reliability is the probability of a system functioning correctly over a given period of time, and the most difficult part of any distributed system is to coordinate the computations so that a correct result is found. Availability is the probability of a system functioning correctly at any given time, and distributed systems typically have the greatest advantage over non-distributed systems in this area. The greater redundancy and reconfigurability of distributed systems allow for very high availability to be designed into distributed systems. Security, the ability of a system to protect the data and identities of its users, is the bane of most multi-user distributed systems. Often there is information which must remain private, or system capabilities which should only be used by certain users, and ensuring security in the system is a difficult task. It is an emergent property, dependant upon all the components and interactions of the system, and typically comes at the cost of ease of use or performance. Safety, the ability of a system to avoid threatening human life, property, or the environment, is typically a larger issue than the idea of distributed systems encompasses.[Storey] While many safety-critical systems are being designed in distributed manners, the issues pertaining to safety in distributed systems usually apply to non-distributed systems as well, and are outside the scope of this paper. A good designer must know which of these four aspects his system must focus on, and the trade-offs inherent in designing for one or the other.
The main concern with reliability is having the computational nodes coordinate effectively with each other. This requires a reliable network, as well as successful protocols for communication between the nodes. Once network performance is assured, the content of the messages must be coordinated. Certain hierarchical structures, such as client-server relationships, in addition to synchronization schemes such as mutual exclusion, priorities, and various sorts of clocks, can be used to order messages among recipients and ensure that conflicts or deadlock do not occur. Finally, data must be organized so that one-copy semantics are preserved, with the degree of replication and coordination determined as necessary for the system.
The availability of distributed systems is often what makes them such an attractive option. Fault detection and masking are possible in the system using voting, N-version hardware and software, and Byzantine algorithms. In addition, some distributed systems can reconfigure around faults, routing through different connections and nodes, and reassigning the duties of failed nodes to other nodes in the system. Graceful degradation is also possible through this method as nodes fail.
Lastly, security is more likely to pose a danger in distributed embedded systems than any other embedded system. The presence of network communications and possibly multiple users across the nodes means that unauthorized users must be kept off the system, and must keep authorized users from viewing or corrupting the data of other users. There are two major aspects to security. The first is authentication, in which passwords and encryption are used to identify users and keep their communications private. The second is protection, in which access to user's data is limited by the user's identity.
These techniques provide a useful toolkit for assembling a dependable distributed system, but they are only a toolkit. A designer must still know how secure his system must be, how reliable its functionality needs to be, and how available the system must be to meet user needs. Once these concerns are understood and meshed with the functionality of the system, then he has everything he needs to build his system. An embedded systems designer who wants to harness the power of distributed systems must understand these concerns and techniques, but once he does, he has a tool for taking advantage of networking and connectivity that is unsurpassed.
Achieving reliability in a distributed system is not an easy task. Communications between nodes must be coordinated, and then the operations of the nodes themselves must also be coordinated. Various network protocols can be used to coordinate communications, as well as different sorts of clocks for timestamps. Once a method for ordering the messages has been determined, then the operations of the nodes must act appropriately. Often, there will be critical sections of code which must access resources without interruption. In these sections of code methods of mutual exclusion that operate in the high latency domain of distributed systems must be found. Finally, the redundancy available in distributed systems allows voting mechanisms that mask out faults and allow correct operation despite errors present in the system.
Coordinating the communication between nodes begins with the network. There are many networks available, varying from Ethernet to Token Ring to CAN and beyond. What is important is to determine what a particular system requires. A real-time distributed system might need timing guarantees that Ethernet cannot provide with its arbitration and retry protocol. On the other hand, the bandwidth and conceivability of Ethernet might be required for another system. With another system, a token based method of message passing may aid in coordinating the operations of the nodes in addition to the communications. The network technology chosen for the system will have its own specifications as to bandwidth, latency, and prevention of conflicts, and what is important is to choose one that fits the requirements of the system.
Once the network technology has been chosen, a communication protocol must be imposed that supports the amount of ordering necessary for the system. Some systems will be able to function without ordering of messages, so that messages arriving out of order will not cause a conflict. Other systems will need to have messages arrive in order from one node to another. Logical clocks can be a solution to this system.[Lamport 78] Each node keeps a local time, and upon receiving a message updates their time to that contained within the message plus one. Each message sent out has the local time included in it, and the local time is incremented. Messages that arrive with timestamps earlier than the local time are dealt with as appropriate to the system. Other systems may need total ordering of messages. In these cases a global clock is necessary. This can be difficult technically, as skew and delay can pose major problems for transmission of the clock.[Lamport 85] Mechanisms such as the Network Time Protocol (NTP) [Mills] do exist to distribute a clock over a widely distributed system, but the overhead for calculating skew and correcting is not trivial, and must be accounted for.
After communications have been coordinated in a system, the operations of the nodes must be coordinated, often with respect to the critical sections mentioned above. In a client-server context, these operations can be coordinated through the server, granting permission for clients to proceed or telling them to halt operation as necessary. Outside of a client server relationship, however, the task becomes more difficult. All nodes in the system must coordinate. In some cases, this can be layered upon the network or communication protocols through tokens or arbitration. In other cases mutual exclusion mechanisms such as mutexes and semaphores must be used. The concept of transactions, lifted largely from the area of databases, has been applied to this problem with great utility as well, both in its two-phase and three-phase flavors. The cost of transactions is made up for in the high degree of reliability it provides. The difficulty lies in implementing these mechanisms in the high latency environment of a distributed system. Often agreement of some sort between nodes is necessary to acquire access to a critical section. There are various agreement protocols running the gamut from full agreement to majority agreement to the partitioning of the system into different groups and requiring agreement from the members of a group to proceed. There are many sophisticated ways to acquire sufficient agreement to proceed, both in terms of performance and correctness, and it is left to the reader to examine the sources at the end of this chapter, particularly Mullender's book, and Chow and Johnson's book, for a more detailed discussion.
Finally, there exists the possibility to construct voting mechanisms to mask out faults in the system. Fail silent errors, in which the faulty component fails to return a result, can be masked by a single additional element which provides a result in the case of failure. For stuck at failures, components can be triplicated for voting to mask out errors, as the two additional elements will correctly mask out the error from the faulty component. For malicious errors, a Byzantine algorithm can be used to mask out errors, in a manner described below. The important thing to remember is that these masking mechanisms will not remove design faults from the system, as all components will fail simultaneously in what is known as common mode error.
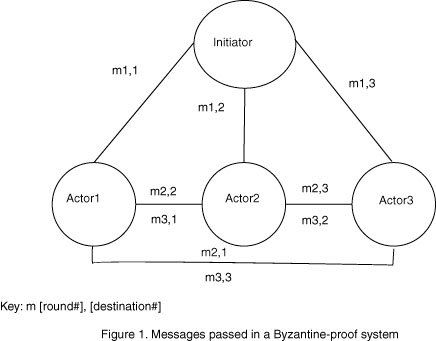
As an example, and to clear up confusion in what can be a difficult recovery mechanism to understand, we will detail the operation of Byzantine error correction. Byzantine algorithms are designed to prevent malicious errors, in which a faulty node provides contradictory messages to other nodes, such as a node telling one node to commit a change, and another to abort it, causing inconsistencies n the system. A system can be made to tolerate up to k Byzantine errors by including at least 3k+1 nodes. The nodes are each connected to the other nodes through k+1 independent communication channels, to allow messages to travel without being modified by the malicious node. The nodes must confer for k+1 rounds of communication in which they send their messages to all other nodes for agreement.[Kopetz] The following example illustrates the principles involved.
Assume a system arranged as in the figure. There are 4 nodes, one initiating the state change and three additional nodes which must agree. The initiating node sends out its message. Next, the other nodes send the message they received to the rest of the nodes. If the initiating node is malicious, it will still send out two messages that are the same, and therefore in the second round consensus will be achieved. If one of the other nodes is malicious, it will send out inconsistent agreement messages, but the functioning nodes will still reach agreement. If two nodes are malicious, then an agreeing node can be made to disagree with the other nodes, preventing consensus. This system can prevent up to one Byzantine failure.[Chow]
Two things should be noted here. The first is that these are binary decisions. For other transmitted values averages or rejection of outliers must be used to come to agreement or consensus, but the problem may be intractable. The second is that we are not concerned with correct behavior, but with consensus. The initiating node may be malicious and send more messages to not change, when the intention was to change, and the result will be a consensus not to change. The system remains consistent, but correct behavior has not been observed.
Once reliability has been achieved, the greatest benefit of distributed systems can be realized: availability. Where reliability is the chance that if the system works, it works correctly, availability is the chance that it is working at a given point in time. The additional computational nodes and paths for communication allow a wide range of possibilities for working around and hiding faults in the system.
One of the weaknesses of a distributed system is that it operates over a network of some sort. Therefore if the network is compromised or broken, the system fails. If there is redundancy built into the network, though, the system can route communications around the break to allow communications to get through. FDDI is a network built around two rings running in opposite directions. A distributed system built on top of FDDI can survive a break in one ring by routing communications in the opposite direction. Should both rings break, there are still paths of communication between any two nodes. Once a second breach in the network occurs, however, the network becomes partitioned, with some nodes becoming isolated from others. In this case, the built in redundancy was not sufficient to contain the number of faults encountered.[Kamat]
The second way to take advantage of the redundancy available in distributed systems is the reassignment of tasks from failed nodes. In a general computing setting, when one node fails, the system can detect the failure and assign another node to performs the tasks on the failed node. As with the redundant voting algorithms described above, common mode failures can still present a problem here. A task that crashes one machine can propagate to another similar machine, and cause the same sort of crash. If more information can be obtained regarding the causes of the failures, then alternate methods can be applied.[Kanekawa]
Another way to improve availability is to provide mechanisms for graceful degradation, in which the system provides lessened utility or effectiveness in the presence of a fault, but still manages to provide some service. As an example, in automobiles the fuel injection system is computer controlled in a manner so as to make the most efficient use of the fuel according to a complex model of the activity in the engine. Should the fuel injection controller fail, its activities can be taken over by the transmission controller at the price of reduced fuel efficiency. The car still runs, but is less fuel efficient.
Finally, all the tools of redundancy that help reliability generally help availability as well. If failures that would cause incorrect functioning are masked out, then often failures that would cause the system not to function can be masked out as well. What is important to remember, however, is that the two goals can work at cross purposes. It may be reliable to require that all nodes agree before committing a change. However, if a single node fails, then the entire system becomes unavailable. A similar exchange occurs in the case of data replication. If data is replicated across many nodes, then it becomes highly available. The difficulty lies in making the data consistent given the chance to change the data and the high latency for notifying other nodes of those changes. If the data is stored in a central server, then consistency is maintained, but availability becomes lower as that data must be transmitted over the network. The requirements for availability and reliability must be weighed against one another, and algorithms, protocols, and guidelines exist for systems requiring varying degrees of each.
Lastly, security is a problem in distributed systems as in few other areas. The nodes and networks are both targets for the system to be compromised. There is more data available, and more possibilities for users to intrude on the space of others in the system. While the majority of the issues involved in security are discussed in that chapter, an overview and the unique challenges posed by distributed systems are described here. As with the other areas, what is important is to know the level of security necessary in the system, and to choose an appropriate level of security to implement.
The first part of any security method is authentication, the unique identification of a user. The most relied-upon method for this is a password of some sort. Encrypted passwords can be used, as well as public key schemes and token based authentication such as is found in Kerberos. The problem lies in discovery of a user's password. There are many exploitable weaknesses in human psychology, but there are technological weaknesses as well. Encryption is often used to disguise a password, but this only works if the encryption cannot be broken. In a distributed system, passwords can be picked up off the network, or intercepted at a node, or taken from storage on a node where passwords are stored, unless properly protected. Since distributed systems tend towards multi-user capabilities, authentication is often a strong concern.
The second part of security is protection, in which a user's data is protected against unauthorized access. Secrecy regarding the existence or non-existence of their data, privacy as to its contents, authenticity of the data presented, and integrity of the data over time must all be provided. Unauthorized access in one way or another compromises these restrictions. The typical protection scheme used is to reduce the data stored to a certain level of granularity, and then provide a matrix of users and their permissions for each granule of data. In this way each user can be given proper access rights to the different items stored in the system. The problem lies in ascertaining the identity of the user, and so protection, even when perfectly implemented, is only as secure as its method for authentication. The problems associated with both authentication and protection are covered in Mullender's book as well as Chow and Johnson's.
The one possible benefit of a distributed system is in restricting the access of intruders. In a single node system, compromise of the node allows total compromise of the system. In a distributed system, an intruder who has access to a single node may not necessarily have access to the entire system. While methods for partitioning in this manner are not completely well known, the potential remains for this to mitigate the consequences of the system's security becoming compromised.
If there is an overall lesson to be learned regarding the implementation of distributed systems, it is to know the requirements of the system. The computational power necessary to fulfil its mission should dictate the number of nodes used. The bandwidth necessary will help determine the network. Reliability and availability will determine the redundancy provided, and the algorithms used for consistency, and the degree of replication present in the system. The potential for harm from unauthorized access will set the level of security necessary. A vast array of techniques and algorithms exists. The difference between designers lies in knowing which technique to use to meet the needs of a particular application.
There are a great number of tools available for distributed systems, but the most useful ones are design tool used to aid in designing a distributed system, rather than tools that are a specific type of distributed system, or networking tools. Of these, two standards are currently attempting to target themselves at distributed systems: the Common Object Reference Broker Architecture (CORBA), and the Distributed Common Object Model (DCOM).
CORBA supports an object-oriented approach in programming. Through its Interface Descriptor Language (IDL) the methods which are to be invoked are specified, and then the objects are written to support those methods. Methods are then called on references to those objects, which may exist on the local node or elsewhere on the network. References are supplied by a naming server, or by an Object Reference Broker (ORB), to which objects register. CORBA is language independent, with translations from the IDL to C, C++, Java, and numerous other languages already specified. It also can provide additional support for encryption, reliable service, and other services depending upon the ORB implementation chosen. While CORBA is an open standard, it relies heavily upon the exact implementation used, which can vary in the additional support it provides beyond the basic interactions. CORBA is currently being developed for embedded and real-time systems.
DCOM is a standard provided by Microsoft, and is propelled by the idea of interfaces. Objects provide references to their interfaces, and each interface provides a method for discovering if it is supported. For example, if we wish to find out if an object supports FooInterface, then we query its generic interface. If it supports that interface, we receive a reference upon which we can call those interfaces. If it does not, then we find that that interface is not supported, and must attempt to find another acceptable interface. At the moment, DCOM is only targeted at traditional computing, but with the increasing use of Intel processors and Windows, it may become a more popular option.
Distributed systems, in general, are somewhat well understood. Most of the underlying mechanics and design principles are understood, but development continues. The main difficulty lies in moving from a centralized control scheme, such as a client server hierarchy, to a decentralized self-regulating control scheme. The latter is often the most efficient and the "right" way to do it, but it is also more complex and much harder to conceptualize and design. When these decentralized systems are better understood, then distributed systems will have taken a large step towards full maturity.
Embedded Communications
Embedded communications form the backbone of any embedded distributed
system. It is the network atop which the system is built, and the
importance of the network and its protocols in a distributed system have
already been discussed. A distributed system designer has to know his
network in order to design well.
Real Time
Distributed systems are often used for the real-time control of multiple
objects, or the real-time transportation of data. Because of the
latencies involved in network communication, the difficulties of scheduling
tasks, and the possibilities of packet loss or data corruption, designing
distributed systems for real time applications is a difficult task. The
improvement in computing power and localization of that computing, however, can
make it a task worth doing.
Fault Tolerant Computing
The compartmentalization of faults and the various techniques for masking them
out that are described here are all steps towards fault-tolerant
computing. Some of them are unique to distributed computing, while others
are merely the application of fault tolerant computing techniques to the
distributed environment.
Checkpoint/Recovery
Checkpointing and recovery is useful technique target at more fault-tolerant
computing. A snapshot of the system state is taken and saved, and if the
system fails the last checkpoint stored is examined and the system returned to
the snapshot stored. It is difficult to do in a distributed system, however,
due to the need to maintain consistency across network latencies, and is
particularly difficult in systems where the nodes are sometimes disconnected
from the system. This is an area of ongoing research.
Security
Security is necessary in most systems open to more than one user, or which
disallow use by some users. Since distributed systems are often
multi-user, and often must prevent unauthorized access, this is a strong
concern in distributed systems of this sort. As more and more embedded
systems become connected to the Internet or become networkable, this will
become a larger and larger concern.
Fault Injection
Fault injection is a technique targeted at measuring a system's ability to
resist causing errors from faults. It has been applied to distributed
protocols and communications to great effect, and is useful in testing new
designs.
Quality of Service
Quality of service concerns often deal with network communications, in
particular latency and bandwidth, and as such intersect with the requirements
that distributed systems place upon their networks. In particular,
quality of service techniques can be used to ensure that a network for a
distributed system meets the requirements, and can add flexibility to a network
to allow it to meet higher demands when necessary.
Distributed systems are not appropriate for every embedded application. In traditional computing, they are largely used in clusters to provide increased computational capability and multi-user access. For embedded systems, distributed designs are much more likely to be used to provide localized computation, such as the different controllers in an automobile, or network-aware devices, such as a WebTV box. Once you know that your design has these requirements, then the principles of distributed design can effectively be applied to your design. The cost of a network and additional processors needs to be justified, however, and should not be used lightly.
Reliability is the main hurdle to be overcome, and the tightness or looseness of interaction in a system will determine the degree of reliability that must designed into it. The degree of availability must also be determined, as the amount of down time is often critical to a system. This increased availability will sometimes come at a cost of reliability. Lastly, the security needs of the system must be determined, again at the cost of reliability or availability. The three areas must be balanced against one another, and it is in this balancing act that a good designer's work will shine through. Once these requirements are solidified, a variety of techniques exists to fulfil those requirements.
Finally, there is still work to be done. Synchronization of distributed systems is still an area of ongoing research, and its application to embedded systems remains exploratory. The benefits that distribution can bring to fault tolerant computing are not fully explored. Security, as almost everyone should know, is still much more of an art than a science, and an often poorly understood one at that. In addition to these details of implementation, there is still not a large body of work helping in the decision as to whether or not a distributed system is useful in a design. While there are some quick and obvious ways to decide this, in some cases it may not be an easy decision. This is especially true for embedded distributed systems, which do not have the quantity of research that traditional distributed systems have. Lastly, the proper use and vulnerabilities of connecting to the Internet are not completely understood, especially not for embedded systems. If the Internet is to be fully taken advantage of, then using and controlling access to and through it must be well-understood principles for embedded designers to employ in their designs.
This paper gives the results of simulation of a distributed real-time system
with dependability features.
This book goes into a little more detail about the more sophisticated
algorithms and ideas, and also connects them to design principles. This
book is geared more towards traditional computing, though, so some of its
contents may not be applicable to embedded designs.
This paper describes reconfiguration in a network in the presence of faults.
This paper discusses an algorithm for graceful degradation, and discusses
some of the difficulties involved.
This book is directed exactly at embedded real-time distributed systems, and
does a good job of describing the typical concerns. However it tends to
present itself as directions to follow rather than potential designs, and isn't
suited to every type of design. Also details the Time Triggered
Architecture, which is a good example of an embedded distributed system.
This paper discusses logical clocks and their operation.
This paper discusses mechanisms for synchronizing physical clocks.
This paper describes the operation of NTP, which distributes time over the
Internet.
This is a good introductory book covering a lot of material. It
discusses a large number of topics and techniques, with an emphasis on the nuts
and bolts of putting a distributed system together.
This paper highlights the impossibility of achieving consensus in
asynchronous systems, and discusses some protocols which attempt to circumvent
the problem.
This book has some basic definitions applying to dependability.
This paper describes a checkpointing algorithm that operates over a network, as in a distributed system.