Ying Shi
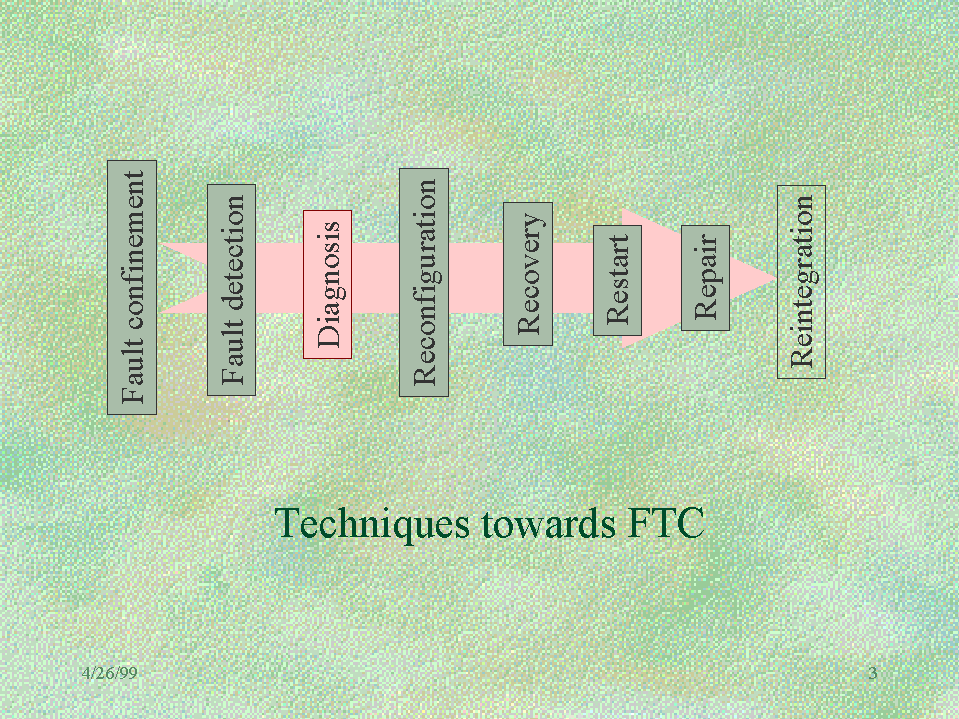
Diagnosis is one of the system failure response stages, as shown in Figure-1. At the first stage of fault confinement, fault effects are limited to one system area, v.s. get propagated (see FT of Ying) and contaminate other system areas; Fault detection stage recognizes unexpected system event has occurred; Diagnosis becomes necessary step when the detection technique does not provide information about the location and/or properties of the failure; Reconfiguration comes into stage when a fault is detected and a permanent failure is located; At the stage of recovery varieties of techniques are utilized to eliminate fault effects; After the undamaged information is recovered, system goes into the restart stage; In the repair stage, we replace those system components diagnosed as having failed; And in the stage of reintegration, the repaired module gets reintegrated into the system.
Diagnosis is an important function in computer systems, both for manual repair and for automatic reconfiguration in fault-tolerant systems. A fault may cause the system to violate its requirements, i.e., to fail. Even if the errors caused by a given fault are masked by redundancy, it is desirable to eliminate the fault. Otherwise, additional faults, accumulating over time, may eventually exceed the fault-masking capabilities of the system and cause system failure. Some form of repair or reconfiguration ability is thus generally necessary, except possibly in fault-masking designs for very short mission times.
Diagnosis is an important aspect of a system's response to failure. Diagnosis involves inferring the process that generated a set of symptoms, results, or outcomes. Diagnosis is a significant proportion of maintenance procedures, not only to isolate the failed component but also to ensure that the repair operation is successful. Generally speaking, diagnosis can be either retrospective or predictive. Retrospective diagnosis seeks to determine what caused a system failure – the “what happened?” question. It can increase system availability by facilitating the quick revival of fallen systems. Predictive diagnosis seeks to determine when a failure will occur – the “what if?” question. Predictive diagnosis (failure prediction) can turn corrective maintenance into preventive maintenance, thereby increasing perceived system reliability. Retrospective diagnosis enables operators and maintainers to assess problems immediately and restore service quickly, while predictive diagnosis can be used to guide preventive and preemptive maintenance. In each case, system downtime is reduced.
Diagnosis is often associated with and sometimes confused with testing. It
is important to understand the distinction between diagnosis and testing.
Testing is a measurement procedure whose goal is to provide information
sufficient for determining whether or not a unit under test responds to a
stimulus in accordance with a prespecified standard. Diagnosis is a
constrained search procedure whose goal is to guide the administration of
tests. Results of testing are often used diagnostically to provide additional
symptomatic evidence for deciding which further tests to perform. In
practice, the two processes – testing and diagnosis – are often mixed
indistinguishably.
The core of specification-based diagnosis is testing, which can be characterized as a black box experiment. Black box testing is to apply stimuli to the input terminals and then observe responses, which are called terminal characteristics, on the output terminals. The terminal characteristics may be electrical (such as a straight-line relationship between voltage and current for a resistor), combinational ( such as an AND gate), sequential ( such as a counter), or even complex systems ( such as a microprocessor on a chip). As the functions of the component become more complex, the kindof testing becomes a problem, for there is less direct control and less direct observability of internal behavior. Also it requires that the manipulation of external inputs must establish a certain condition in a component deep in the recesses of the black box, and the outputs of that component must be propagated to the output terminals. As system complexity increases, not only are there more components, but each component is also harder to test.
Testing involves more than just the maintenance activity, it comes into act through most of the stages in the life of a digital system. During the first stage, specification and design, the faults of most concern are logic errors in the algorithms. During the prototype development stage, any number of failures are possible, including logical design errors, wring mistakes, incorrect time- all of which can lead to different functional behavior. Failed components can also cause altered functional behavior. The former, designated as a logical fault. With logical faults, the proper algorithm must ultimately be distinguished from any arbitrary algorithm. Here testing involves many similarities to proving programs correct; However, given a correct design, there are many fewer faulty behaviors caused by a malfunction. The component interconnections limit the number of realizable fault behaviors. In prototype development, the final errors in the design and proposed implementation are sought by testing. Physical connectivity may cause timing errors and coupling between multiple signal lines. Subjecting a small number of systems to design maturity testing establishes baseline failure manifestations and MTTF.
During the manufacturing and installation stages of a system, the main goal
is acceptance testing. Here, problems of design have been resolved, and testing
focuses on the mass-produced black boxes. The faults are primarily structural ,
but there may be any number of them resulting from the assembly process. When a
system malfunctions during the operational stage, maintenance testing is used
to isolate and repair faults. This form of testing is perhaps the easiest
form of testing, since at this stage there are few structural faults.
Frequently, maintenance tests are run during system idle time to detect
failures and increase confidence in the correct functioning of the
system. There is a significant trend toward remote diagnosis, either to
pinpoint failures before dispatching field service personnel or to issue
instructions for customer repair.
At any of the stages of system life, testing can occur at each level in the
physical hierarchy. It is extremely important to understand at what level and
stage a testing technique is aimed. Thus, Table-2 classifies types of testing
by combining some of the levels and stages. At the design stage, issues
around testings are design validation, lower confidence level test, sequential
probability ratio test, and weibull sequential test. At the production
stage, there are paramitric testing, acceptance testing, system-level testing,
and design for testability. At the field operation stage, we have testing
methods such as margining, built-ins, and synthetic load.
Table-2 Testing based on system level and life stage
| Level \ Stage-> | Design | Production | Operation |
| Circuit | Simulation | Parametric | Margining |
| Logic | simulation | Acceptance test/incoming inspection | Diagnostics/built-in test |
| System | Design maturity test | Process maturity test | Synthetic load/remote diagnosis |
Analysis of system error files indicates that many permanent hardware failures are preceded by a period of instability . Frequently , the period of instability can be detected by observing trends. If a characteristic symptom can be identified in the trend data, the diagnostic time and hence the period of instability can be reduced. This approach is often called trend analysis or symptom-based diagnosis.
Symptom-based diagnosis, which relies almost entirely on observed
performance of the system under diagnostic procedure, is relatively new.
It was explored in two independent efforts in the early 1980s. Maxion employed
a real-time monitoring technique to gather data about disk failures in a
distributed system. Analysis of this data yielded competent faults. Tsao used
"tuple" analysis to group symptom data into meaningful units. These
units, or tuples, were then mapped into fault mechanisms. When a particular
tuple was observed during normal operation, its underlying fault mechanism
could be inferred from previous experience. Lin&Siewiorek extended these
ideas by developing the frame dispersion algorithm for determining the
relationship between errors by examining their closeness in time and
space. Maxion & siewiorek and Maxion applied similar techniques to
diagnosis of communication networks. This work involves a real-time
problem-solving entity called a diagnostic server. The diagnostic server
is comprised of four main elements: a knowledge kernel in which are kept
general and domain-specific problem-solving strategies; an information
gatherer, or sensor, that collects system performance data relevant to the
problem at hand; and hypothesis generator that forms a ranked set of hypotheses
based on various heuristics; and an experimenter, or effector, that provides
mechanisms for confirming or denying hypotheses. The system, though in
its early stages of development, has been successful in identifying a number of
network performance anomalies.
Methods of Analysis
One trend analysis method, called tuple extraction or tupling, as mentioned above [Tsao and Siewiorek,1983], employs a data grouping or clustering technique . Tuples are clusters, or groups, of event-log entries exhibiting temporal or spatial patterns of features. This approach to the data clustering technique is based on the observation that because computers have mechanisms for both hardware and software detection of faults, single error events can propagate through a system, causing multiple entries in the event log. Tuple extraction clusters those entries into tuples, collections of machine events whose logical grouping is based primarily on their proximity in time and in hardware space. A tuple may contain from one to several hundred event-log entries. Formation into tuples reduces the number of logical entities in an event log. Also matching algorithms are used to determine the uniqueness of a tuple, which further reduces the volume of log information and demonstrates the validity of the "hierarchy of significance" of data in a tuple.
The concept of observing system trends for failure prediction was investigated by Nassar around mid eighties, although this method has been neither thoroughly tested nor implemented, at least some results clearly indicate that failure prediction based on an increase in error rate, a threshold error number, a CPU utilization threshold, or a combination of these factors may be feasible. And soon Iyer developed a probabilistic model to characterize the relationship among errors recorded in a system error log, which was used to automatically detect symptoms of frequently occurring persistent errors in two large control data cyber systems.
The Dispersion Frame Technique(DFT) was developed, based on the
observation that electromechanical and electronic devices experience an
increasing error rate prior to catastrophic failure. The technique determines
the relationship between error occurrences by examining their closeness in time
and space. As general case is that users tend not to tolerate too much system
defects before the repair, so the data points able to be collected from the
event log are not sufficient enough to apply those existing fairly accepted
statistic tools, and this is the motive for the DFT heuristic technique, who
makes decision based on as few as three to five prefailure messages to predict
system failure behavior.
Impact of Symptom-based Diagnosis
There are several reasons to go after symptom-based diagnosis. Strategies for sumptom-based diagnosis closely reflect the strategies employed by personnel performing troubleshooting, thus making symptom-based diagnosis easier to understand and follow. The symptoms on which the approach is based are frequently more accurate indicators in a specification-based approach. Moreover it is a common observation that standard diagnostic programs can, and hence are often incapable of replicating a failure.
During the second half of the decade of the 1970s, Digital Equipment
corporation started a shift from specification-based diagnosis, in which the
field service engineer would execute diagnostic programs in an attempt to
recreate the failure, to symptom-based diagnosis, in which error data is
analyzed to capture information about the failure. The latter approach, termed
symptom-directed diagnosis (SDD), is based upon techniques similar to those
outlines in the previous section and is embodies in programs such as SPEAR(
systems package for error analysis and reporting) and VAXsim-PLUS. These
programs analyze error log data using heuristically established rules to locate
the failing FRU. From the distribution of onsite time spent by a field engineer
when specification-based diagnosis was prevalent, the vase majority of the time
was spent executing diagnostic programs and observing the system to identify
the problem, whereas only 10 percent of the time was spent making the physical
repair, and a further 15 percent of the time was devoted to validating that the
repair activity fixed the original problem. SDD, in conjunction with the DEC
Remote Diagnostic Center, analyzes the system prior to dispatching a field
service engineer; this results in a two thirds decrease in on-site time. SDD is
not only a powerful technique for reducing repair time but also it
quickly identifies problems, thereby decreasing the number of system crashes
and increasing system availability.
Practical Problem with Diagnosis
However, an important practical problem in diagnosis is discriminating between permanent faults and transient faults. In many computer systems. the majority of errors are due to transient faults. many heuristic methods have been used for discriminating between transient and permanent faults; however, rarely is there works stating this decision problem in clear probabilistic terms.
The purpose of diagnosis is often limited to identifying the hardware module(s) affected by faults. However, to choose the right fault treatment action it is also necessary to discriminate between permanent and transient faults. With transient faults, modules momentarily become prone to behaving erroneously, though they do not suffer any permanent damage. The natural way of dealing with a transient fault is to keep using the affected module, after recovering any data error caused by the transient fault. In many computer systems, transient faults are known to be the great majority of causes of errors. However, discriminating between transient and permanent faults is difficult.
Diagnosis is based on the observation of erroneous behavior. A general description of diagnosis is as follows. A module( which, depending on the specific design, may be as small as a subset of a chip or as large as a whole computer or more) is monitored, either by observing side effects of its intended computations (typically, signals from error-detection mechanisms) or by applying test procedures every now and then and observing the module's response. Some of the observed behaviors can be diagnosed as erroneous, in the sense that they would not happen unless there is a fault in the system. But a module may behave erroneously for different reasons: a permanent fault, a transient fault or propagation of errors from another module. decisions about fault treatment should be quite different in the three cases, yet the symptom along is insufficient for deciding among them.
Compared to "ordinary" reliability modeling, reasoning about diagnosis is somewhat counter-intuitive. Reliability modeling predicts the probabilities of certain sequences of events given some assumptions. the model plays the role of an omniscient observer. Instead, a diagnostic procedure takes these assumptions, this set of sequences and their probabilities as inputs, but can not depend on knowing the real sequence under way, and involves questions like " if I observe certain symptoms, which are consistent with more than one of the possible sequences, which sequence is really taking place?"
Designers have used many heuristics for discriminating between transient and
permanent fault, spanning from simple retry to rather sophisticated off-line
error log audit and trend analysis. Heuristics are suggested by intuitive
reasoning, and then validated by experiment or modeling. Most on-line
techniques use thresholding schemes. They count errors, and when the count
crosses a pre-set threshold a permanent fault is assumed.
Symptom-based diagnosis is rapidly becoming the preferred approach for system-level diagnosis during operational life. Based on the observation that systems usually shows a period of potentially more and more unreliable behavior prior to a catastrophic failure, trends can then be identified and used to isolate the faulty field replaceable unit. If the system has been designed to tolerate these intermittent faults, the user will perceive no system outages during diagnosis. Trend analysis develops a model of normal system behavior and watches for a deviation that signifies the onset of abnormal behavior. Since normal system workloads tend to stress systems differently than specification-based diagnostics, their workloads will uncover problems that are not stimulated by test programs. Trend analysis can also adaptively learn the changing normal usage pattern of individual systems.
I'd like to mention besides is that a new trend in diagnosis employs tools
and techniques from artificial intelligence to perform automatic diagnosis of
complex systems.