Dependable, Online Upgrades in Distributed Systems
I take a holistic approach and focus on upgrading distributed systems end-to-end. I identify the leading causes of both unplanned and planned downtime due to upgrades in large-scale distributed systems, I address them through a new upgrading approach, and I propose a new methodology for evaluating the dependability of online upgrades.
Traditional fault-tolerance approaches concentrate almost entirely on responding to, avoiding, or tolerating unexpected faults or security violations. However, scheduled events, such as software upgrades, account for most of the system unavailability. Historically employed in the telecommunications industry, online upgrades are now required in large-scale systems, such as electrical utilities, assembly-line manufacturing, customer support, e-commerce, banking, etc.
I establish an upgrade-centric fault model, by analyzing independent sources of fault data through statistical clustering techniques (widely used in the natural sciences for creating taxonomies of living organisms). My model focuses on human errors in the upgrade procedure, which break hidden dependencies (e.g., specifying wrong service locations, creating database-schema mismatches, introducing shared-library conflicts) in the system under upgrade. There are four common types of upgrade faults:
- Simple configuration or procedural errors (e.g., typos)
- Semantic configuration errors, which indicate a misunderstanding of the configuration directives used
- Broken environmental dependencies (e.g., library or port conflicts)
- Data-access errors, which prevent the access to persistent data
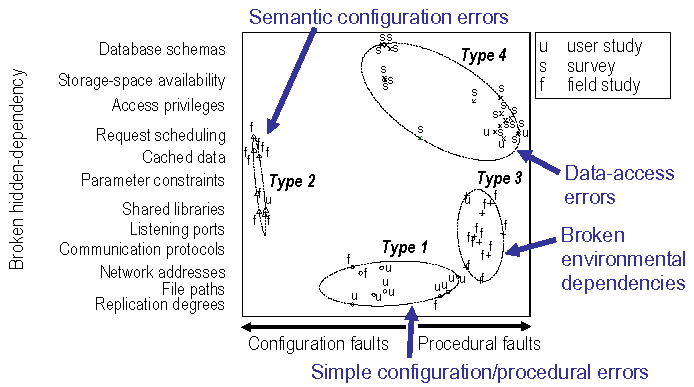
These faults represent the leading causes of upgrade failure in distributed systems. I also identify incompatible schema changes and computationally-intensive data conversions as the leading causes of planned downtime in a popular Internet system (Wikipedia). Previous approaches—which focus on upgrading individual components of distributed systems rather than performing end-to-end upgrades—often induce unplanned downtime, by breaking hidden dependencies in the system under upgrade, and that they cannot always prevent planned downtime, in the the presence of complex schema changes.
I address these causes of downtime through a system called Imago [Middleware 2009]. Imago provides the AIR properties:
- Atomicity: At any time, the clients of the system under upgrade access the full functionality of either the old or the new versions (but not both). The end-to-end upgrade is an atomic operation.
- Isolation: The upgrade operations do not change, remove, or affect in any way the dependencies of the production system (including its performance, configuration settings and ability to access the persistent data).
- Runtime-testing: The upgraded system is tested under operational conditions.
By installing the new version in a parallel universe (a distinct collection of resources), Imago isolates the production system from the upgrade operations and avoids breaking hidden dependencies. Imago performs the end-to-end upgrade atomically, while enabling the complex data and schema conversions that commonly impose planned downtime. I evaluate the dependability of online-upgrade approaches using my upgrade-centric fault model to drive fault-injection experiments. This suggests that Imago is more resilient than previous approaches to the common upgrade faults. Moreover, Imago can prevent unplanned downtime during end-to-end upgrades of distributed systems.
Imago harnesses the opportunities provided by new technologies, such as cloud computing, to reduce resource overhead by temporarily leasing hardware and storage resources during the upgrade. Through the separation of concerns between the functional aspects of the upgrade (e.g. data conversion) and the online-upgrade mechanisms (e.g. atomic switchover), Imago enables an upgrades-as-a-service model [FAST 2010]. This approach has the potential to eliminate planned downtime for competitive upgrades. Amazon.com recently awarded me a research grant [Amazon Research Grant, 2009], for conducting a large-scale experiment (350 machines and 3 terabytes of data), which emulates a major upgrade of Wikipedia, using Amazon's cloud-computing infrastructure.
Grants
- "Imago, an approach for removing leading causes of software upgrade failures via upgrades-as-a-service," Amazon Web Services
Publications
Conference and Workshop Publications
-
I. Neamtiu and T. Dumitraş
Cloud Software Upgrades: Challenges and Opportunities
IEEE Workshop on the Maintenance and Evolution of Service-Oriented and Cloud-Based Systems (MESOCA) 2011
-
T. Dumitraş and P. Narasimhan
Upgrades-as-a-Service in Distributed Systems
Work-in-Progress Session at FAST 2010
-
T. Dumitraş and P. Narasimhan
Why Do Upgrades Fail And What Can We Do About It? Toward Dependable, Online Upgrades in Enterprise Systems
ACM/IFIP/USENIX Middleware Conference, Nov.-Dec. 2009 (LNCS 5896)
[Supplemental information] -
T. Dumitraş and P. Narasimhan
Toward Upgrades-as-a-Service in Distributed Systems
Poster Session at Middleware 2009
-
T. Dumitraş
Dependable, Online Upgrades in Enterprise Systems
Doctoral Symposium at OOPSLA 2009
John Vlissides Award -
T. Dumitraş
Dependable, Online Upgrades in Enterprise Systems
ACM Student Research Competition at OOPSLA 2009
First Place -
T. Dumitraş
Dependency-Agnostic Online Upgrades in Distributed Systems
Student Forum at DSN 2007 -
T. Dumitraş, J. Tan, Z. Gho and P. Narasimhan
No More HotDependencies: Toward Dependency-Agnostic Online Upgrades in Distributed Systems
USENIX Workshop on Hot Topics in System Dependability (HotDep), Jun. 2007
- T. Dumitraş, D. Roşu, A. Dan and P. Narasimhan
Impact-Sensitive Framework for Dynamic Change-Management
DSN Workshop on Architecting Dependable Systems (WADS), Jun. 2006
Book Chapters
-
T. Dumitraş, D. Roşu, A. Dan and P. Narasimhan
Ecotopia: An Ecological Framework for Change Management in Distributed Systems
Architecting Dependable Systems Vol. IV, C. Gacek et al., eds., Springer-Verlag, 2007 (LNCS 4615)
Workshop Proceedings
-
T. Dumitraş, I. Neamtiu and E. Tilevich, eds.
Proceedings of the 2nd ACM Workshop on Hot Topics in Software Upgrades (HotSWUp), Oct. 2009 -
T. Dumitraş, D. Dig and I. Neamtiu, eds.
Proceedings of the 1st ACM Workshop on Hot Topics in Software Upgrades (HotSWUp), Oct. 2008
Technical Reports
-
T. Dumitraş and P. Narasimhan
No Downtime for Data Conversions: Rethinking Hot Upgrades
Technical Report CMU-PDL-09-106, Carnegie Mellon University, Jul. 2009 -
T. Dumitraş, S. Kavulya and P. Narasimhan
A Fault Model for Upgrades in Distributed Systems
Technical Report CMU-PDL-08-115, Carnegie Mellon University, Dec. 2008
[Supplemental information]
Other Publications
-
T. Dumitraş, F. Eliassen,
K. Geihs, H. Muccini, A. Polini and T. Ungerer
Testing Run-time Evolving Systems
Self-Healing and Self-Adaptive Systems, A. Andrzejak et al., eds., Dagstuhl Seminar Proceedings, no. 09201, May 2009